PdfTableExtract
When to use the PdfTableExtract Activity
Use this activity when you want to extract table's data from a specified page in the PDF Document.
Figure 1

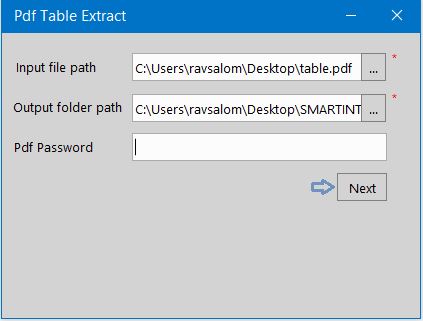
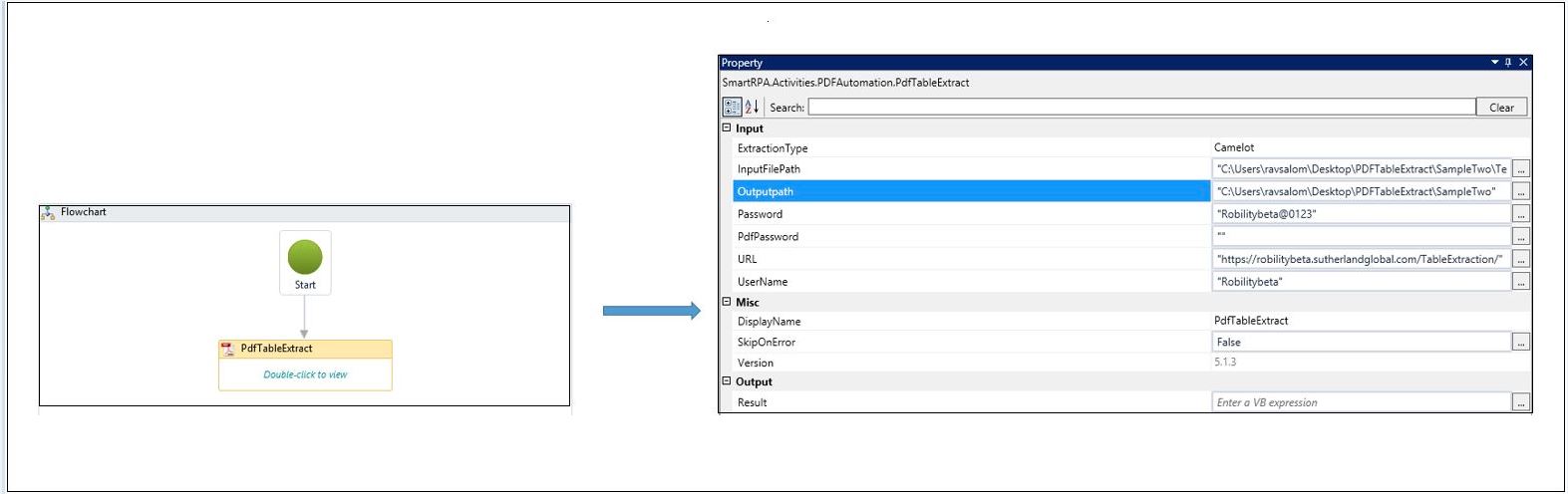
Drag and drop a PdfTableExtract activity onto the canvas. As soon as you drag and drop a PdfTableExtract activity, the PDF Table Extract Screen will be enabled.
Specify the Input File Path with the file name to extract the table. Please be informed that the input file should contain only one page.
Specify the Output Path to store the extracted table data in a CSV format.
Specify the Password only if the PDF is protected by a password. Click on the Next button to enter more details.
Figure 2
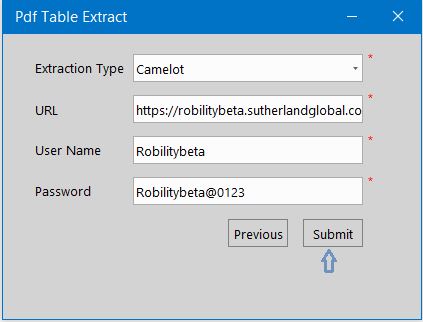
Select the Extraction type from the dropdown.
Please use the provided URL, Username and Password, which are as follows:

Enter the URL, Username and the Password.
Submit. All the entered values will be updated in the Property window.
Figure 2.1
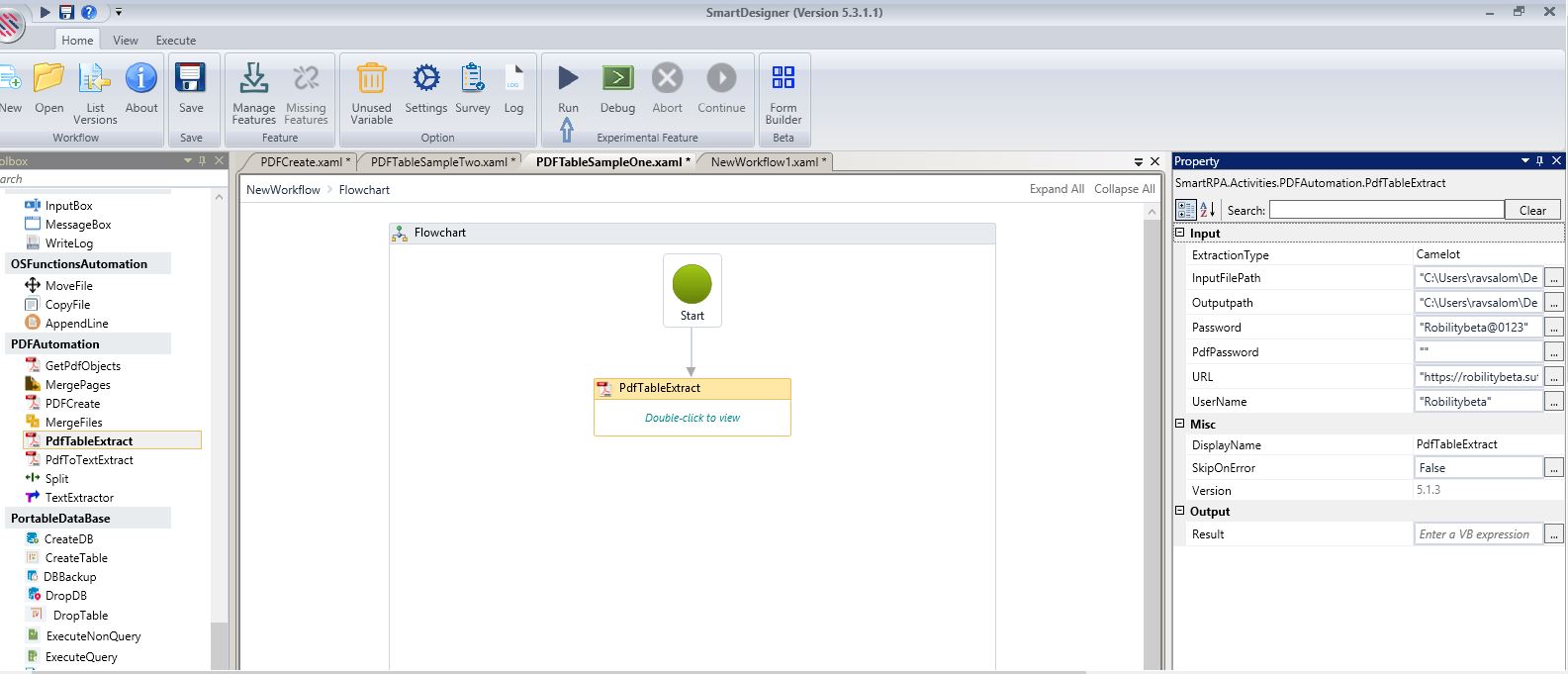
Display Name and version number will be auto populated. Specify whether you want to skip on error or not. After filling in all details, Execute the workflow.
Figure 3
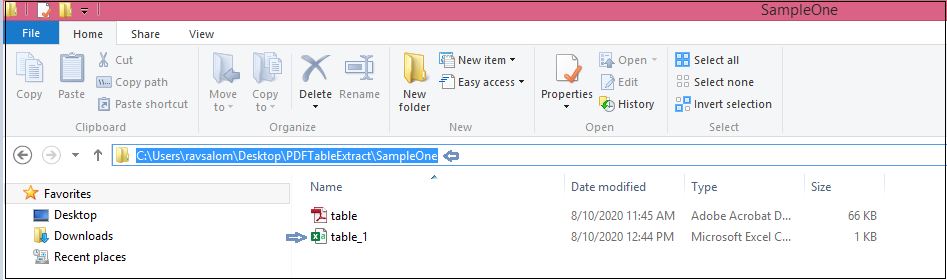
The extracted table data will be available in the CSV file in the specified path. The extracted CSV file name will be same as the input file name with an under score and its corresponding table count.
Figure 4
The table data will be available in the CSV format.
Figure 4.1
The same steps are to be followed if you want to extract more than one table found in the same page. For example, If there are two tables, it will return the extracted data in two CSV files. Fill all pertaining details in the appropriate fields and Execute.
Figure 5
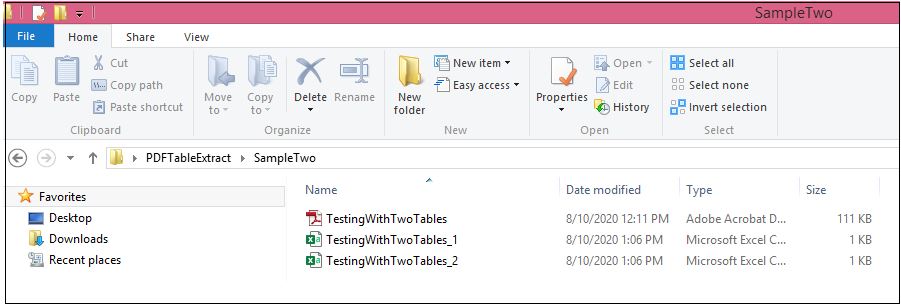
The extracted data from two tables will be available as two CSV files in the specified path
Figure 6
Note:
- In the output file path, if the file name already exists, it will be overwritten.
- The extracted CSV file name will be same as the input file name with an under score and its corresponding table count. e.g. File Name_ 1, 2 ,3, etc.