Text Detection
This activity is used to easily locate and extract text within images, including text in images of natural scenes such as Graffiti on walls, road signs or license plates, text over objects, such as clothing, mugs, etc., and text on screen such as captions or news. When analyzing an image, Text in Image will return the detected text description, along with a confidence score, for each detected words and lines.
Technical Reference:
|
|
INPUT |
ImagePath: Specify the path of the image file that has to be processed. |
|
MISC |
Display Name: Displays the name of the activity. You can also customize the activity name to help troubleshoot issues faster. This name will be used for logging purposes. |
|
|
SkipOnError: It specifies whether to continue executing the workflow even if it throws an error. This supports only Boolean value “True or False”. By default, it is set to “False.” True: Continues the workflow to the next step False: Stops the workflow and throws an error. |
||
|
Version: It specifies the version of the AmazonRekognition feature in use |
||
|
OUTPUT |
Output: This is not a mandatory field. However, to see the text detection result, declare a variable here. |
|
|
Result: Declare a variable here to validate the activity. It accepts only Boolean value. |
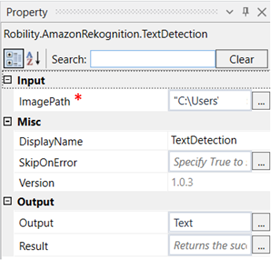
*Mandatory fields to execute the workflow

The following example illustrates on how we can use the text detection activity to derive the text and the confidence score of each word in the given image.
Example:
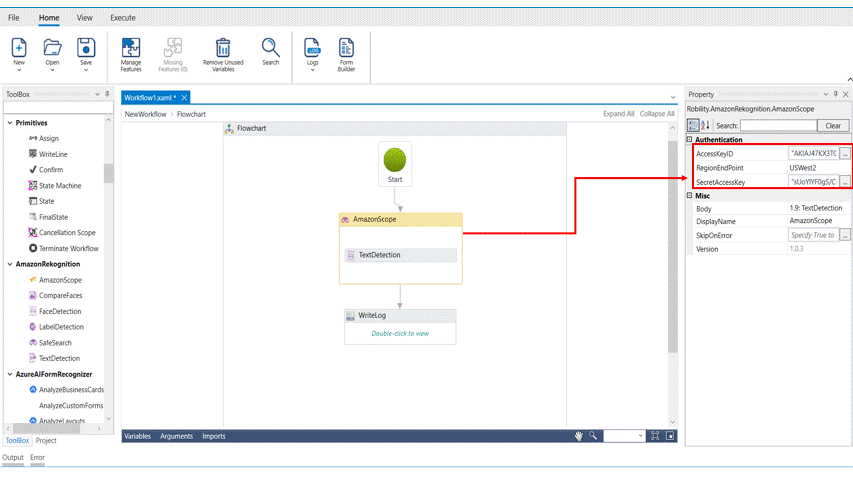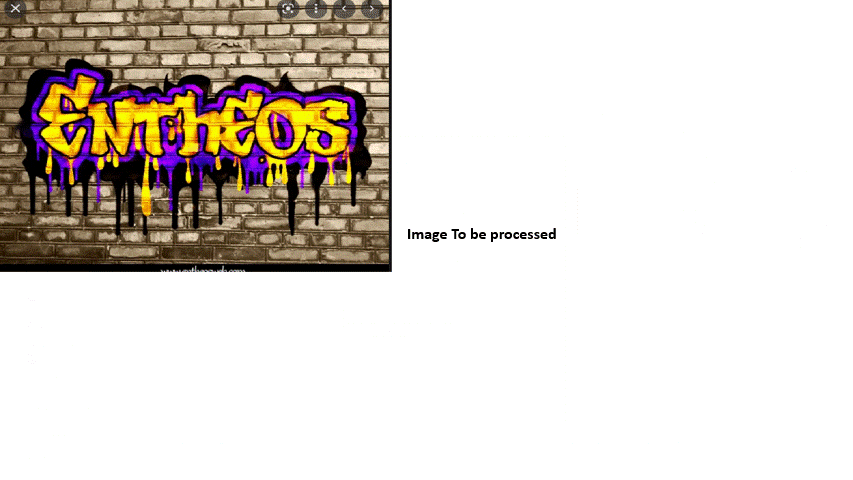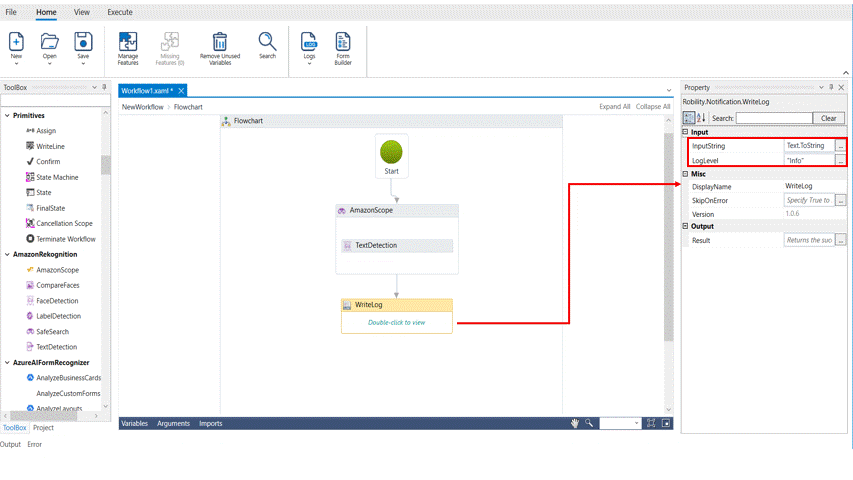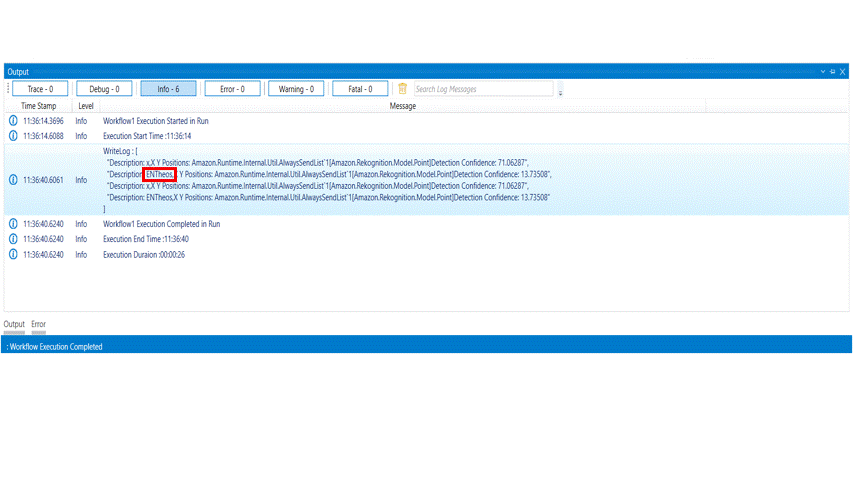
1. Drag and drop an amazon scope activity.
2. Enter the Access key ID, region end point and secret access key.
3. Drag and drop a text detection activity into the amazon scope
4. Click on the activity.
5. Enter the file path of the image which has to be processed
6. Enter the declared variable in the output box to view the result. Here it is Text.
7. Drag and drop a write log activity below the amazon scope.
8. Enter the same declared variable in the input string.
9. Enter the log level as “Info.”
10. Execute the activity.
The bot executes the activity, derives the text for the given image and gives the output with the confidence score of each word.