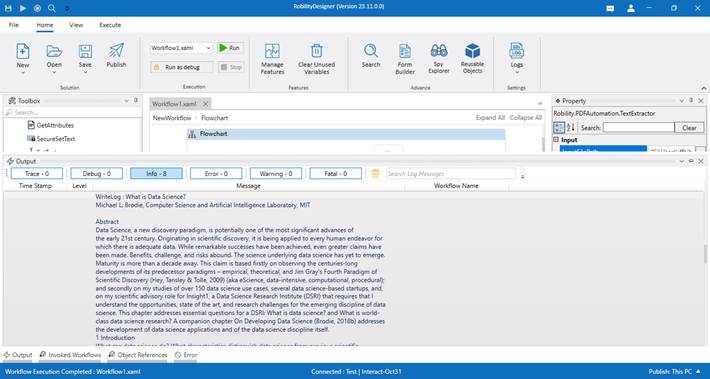
This activity assists the user in extracting the content from the specified pages
of a PDF and storing it as a variable.
Technical Reference
|
|
INPUT |
InputFilePath: This parameter specifies to provide the “Path” of the input pdf from where the text needs to be extracted.
You can either hardcode the values in the “String” variable or pass the values as “String” datatype.
This parameter accepts values in “String” datatype. |
|
Password: This parameter is used to specify the password if the pdf is protected.
You have the option to either hardcode the values in the “String” variable or pass the values as “String” datatype.
When the option is left blank, the password will not be considered.
This parameter accepts values in “String” datatype. |
||
|
Range: It indicates to specify the “page” range to read and extract the text from the specified pages only.
You have the option to either hardcode the values in the “String” variable or pass the values as “String” datatype.
By default, it will be specified as “ALL”.
This parameter accepts values in “String” datatype. |
||
|
MISC |
DisplayName: Displays the name of the activity. The activity name can be customized, which aids in troubleshooting. |
|
|
SkipOnError: Specify the "Boolean" value as "True" or "False."
True: Continue executing the workflow regardless of any errors thrown. False: Halt the workflow if it encounters any errors. None: If the option is left blank, the activity will, by default, behave as if "False" were chosen. |
||
|
Version: It indicates the version of the feature being used. |
||
|
TEXT |
Result: It provides the ability to view the execution status of the activity. It returns values in "Boolean."
True: Indicates that the activity has been executed successfully without any errors. False: Indicates that the activity has been unsuccessful due to an unexpected error being thrown. |
|
|
Text: It returns the output of the activity as the text extracted from the specified pdf document. It returns the output in “String” datatype. |
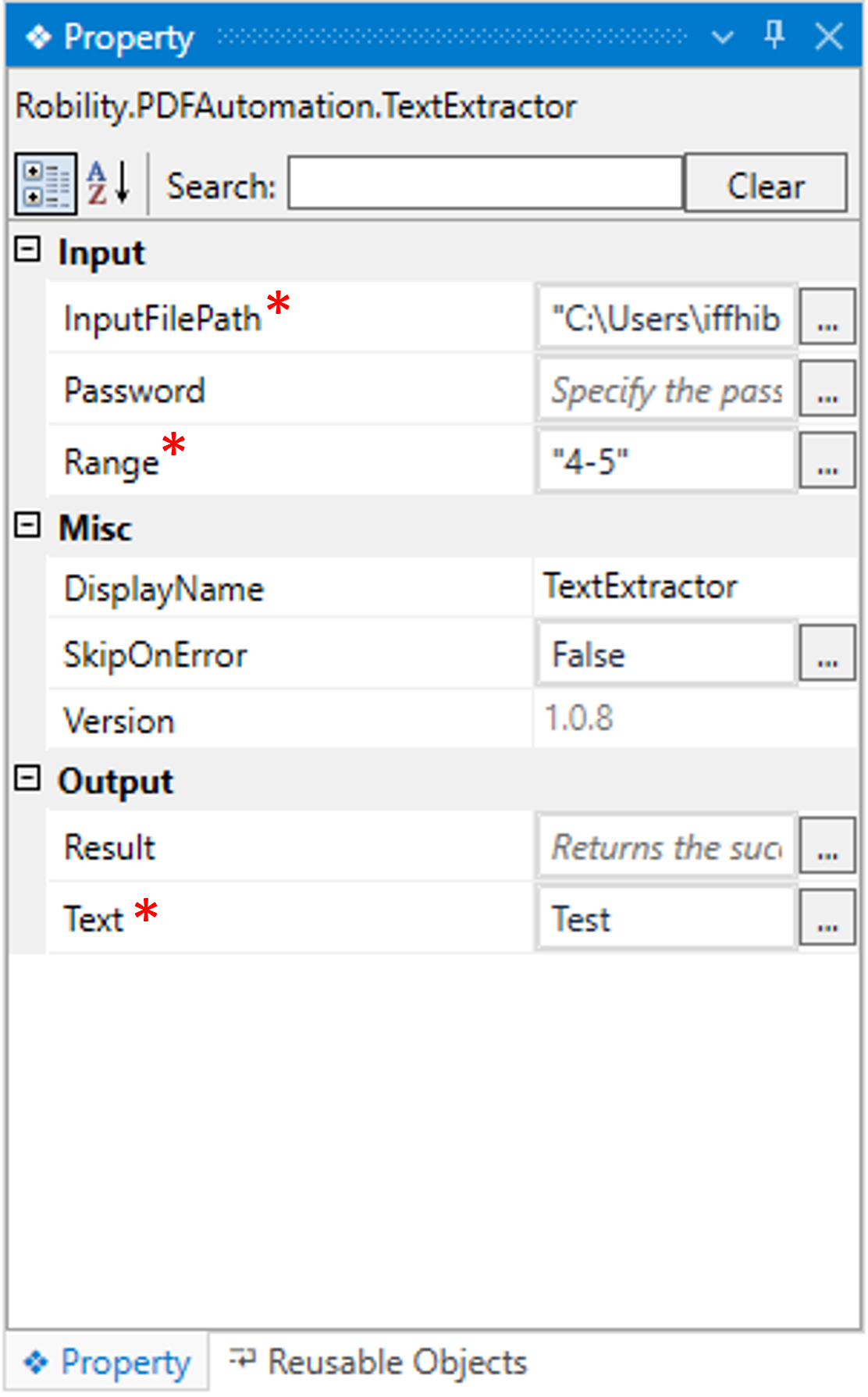
* Represents mandatory fields to execute the workflow

Here's an example of how the “TextExtractor” activity works in the workflow –
The following is a simple example that demonstrates how to extract the content
from the specified pages of the provided input PDF document.
1. Create a solution for building a workflow.
2. Install the "PDF Automation" feature from the "Manage Features" menu.
3. Drag and drop the "TextExtractor" activity onto the designer pane and set it as
the “Start Node.”
4. Double-click the activity to provide the essential details.
a. Here, I am providing the “InputFilePath” as the path of my PDF document to
read and extract the text from the PDF.
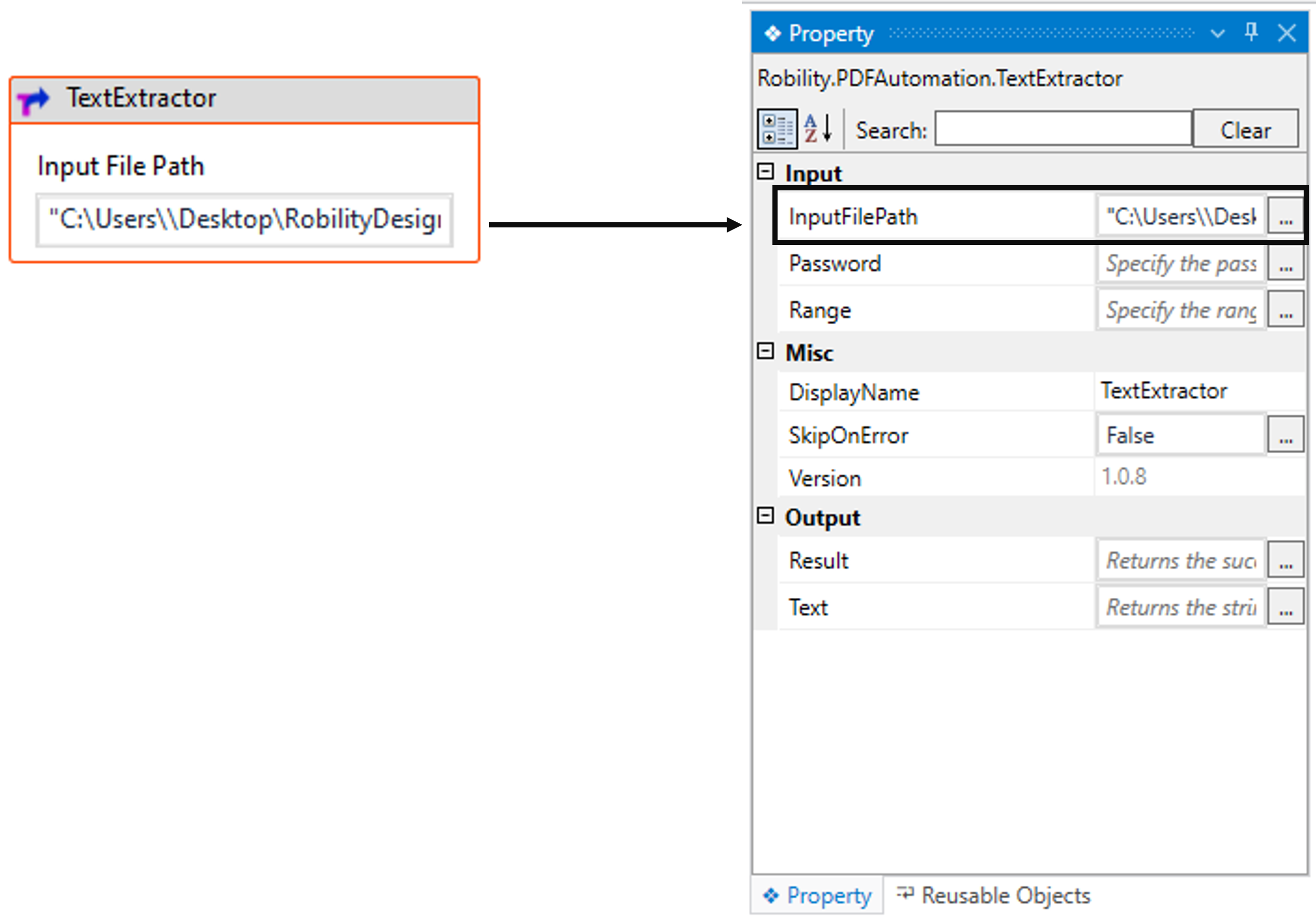
b. Navigating to the “Range” in the properties to specify the page range to
extract.
i. Here I am specifying the page range as “2”.
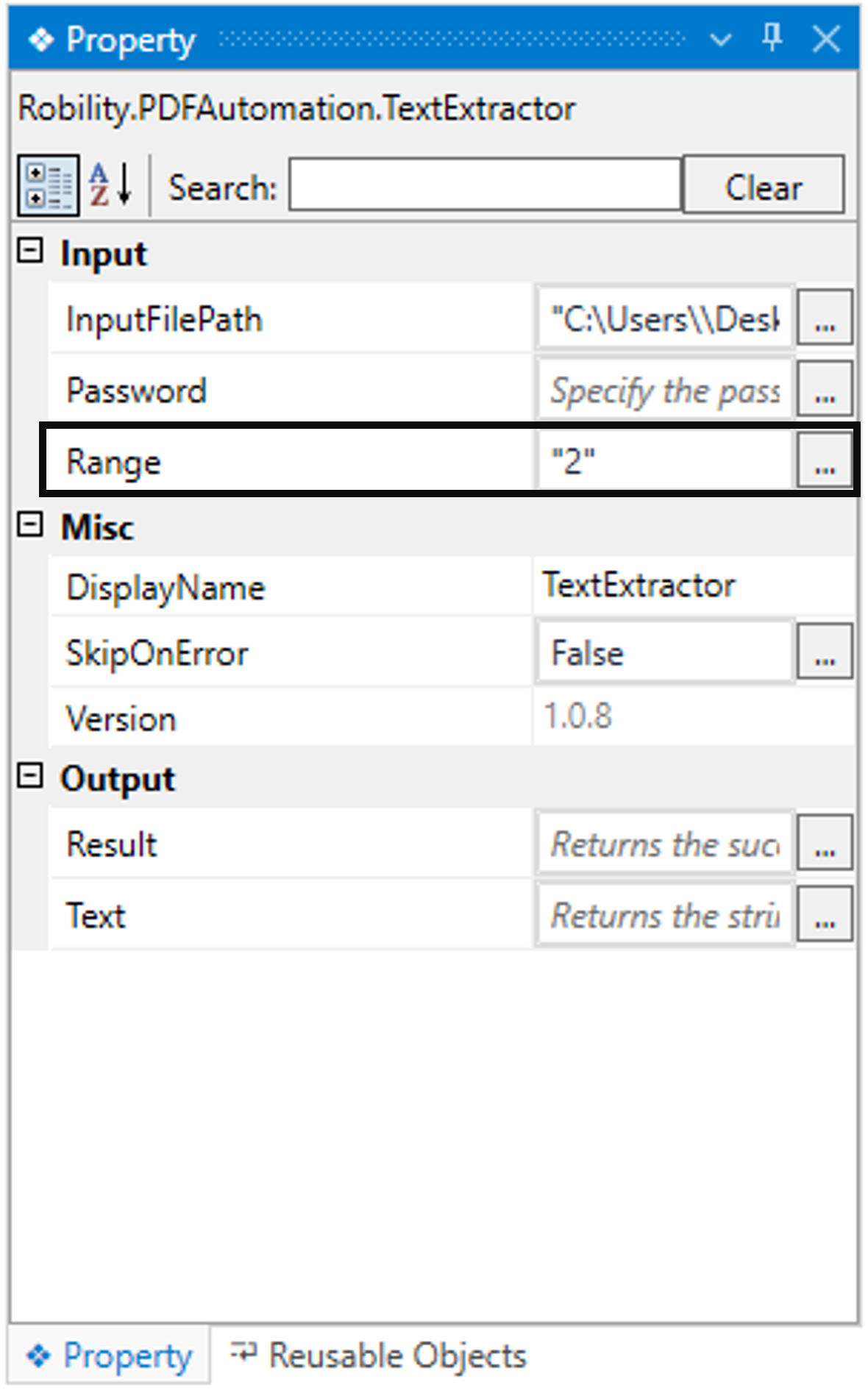
c. Now, moving to the “Text” in the output section of the properties to
declare a variable to store the output in a variable.
i. There are two methods to store the spied value in the variable.
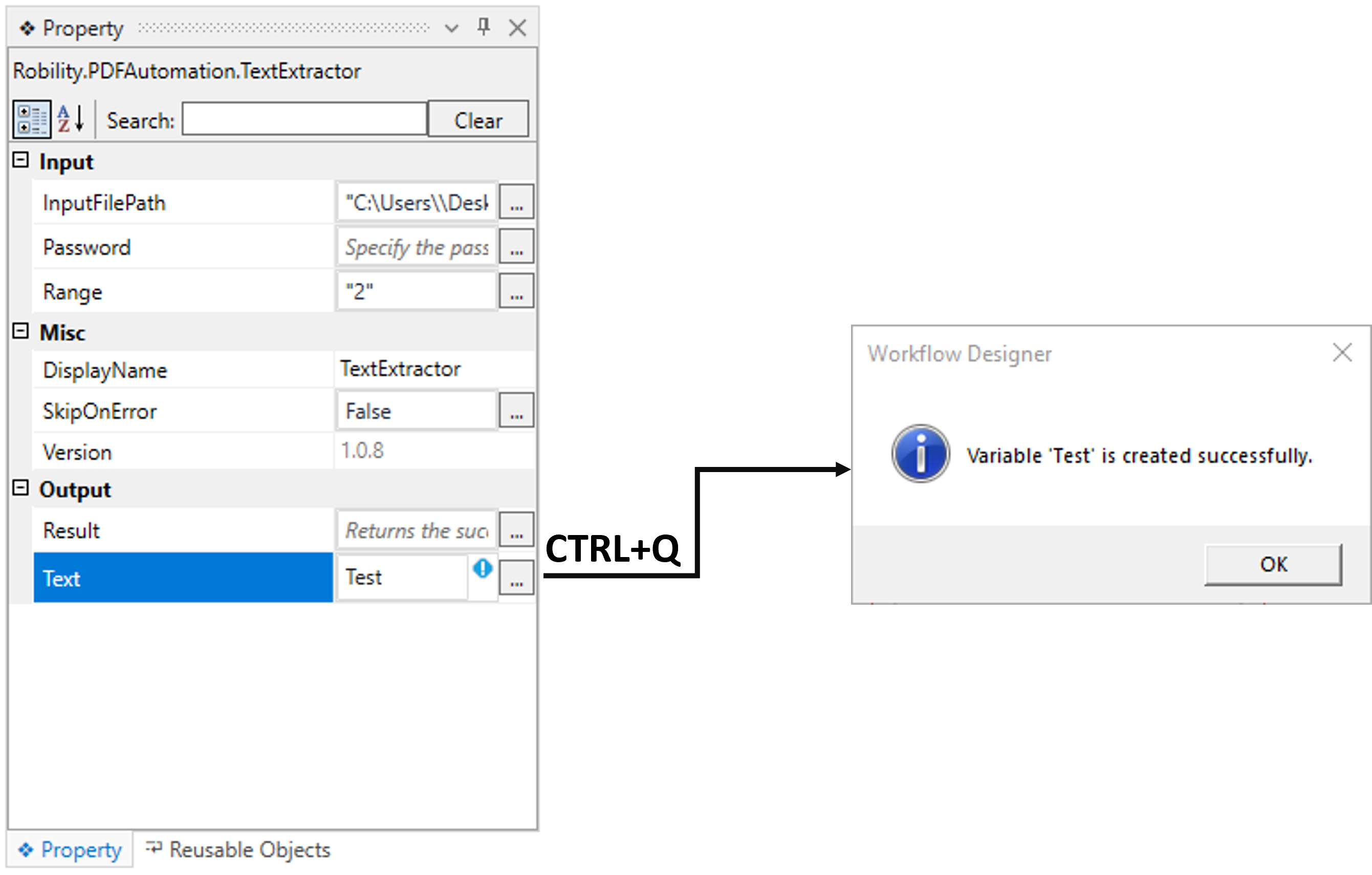
ii. Method 1: Double-click on the variable parameter “Text” in the “Output”
section and enter a name that helps you easily identify it in the flow. Here,
I'm using the name "Test" and using the shortcut key "Ctrl+Q" to create
the variable.
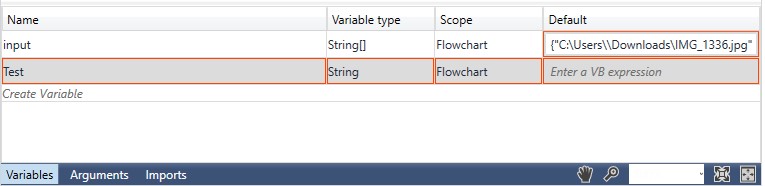
iii. Method 2: Click on the variable pane, enter your preferred name
(here, I'm using "Test"), and choose the data type as "String" since the output
value accepts the string data type.
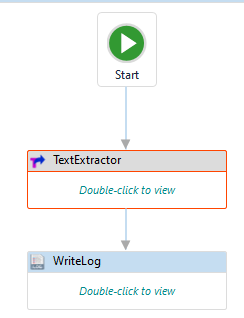
5. You can add a write log activity next to the “TextExtractor” activity to view
the output.
6. Now, execute the workflow to view the results.
Below is a sample of the output of the activity.