
This activity is used to parse the documents to extract the text, data table and
Json format from the specified document using the Google AI API account.
Steps to create Project ID
To automate with Form parser activity, you need to create a project through
Google Document AI API, follow the below steps.
Step 1: Create a Project inside the Google Cloud Platform, click here to
creating and managing projects. Please use a valid Gmail Account for
accessing into the portal. Make sure to keep a note of your Project ID,
which will be used in the activity.
Step 2: Once project ID is created, you need a Google Cloud Service
Account inside your project, click here to create a service account.
Step 3: Mention the role as “Owner” while creating the service account.
Step 4: Download the Service Account Key and save it in a local folder.
Follow the below link for detailed step by step procedure,
https://cloud.google.com/document-ai/docs/setup
Step 5: Once the private key is downloaded, Enable the Cloud Document AI
API for your project. Follow the below link for enabling and disabling this API,
https://cloud.google.com/service-usage/docs/enable-disable
Technical Reference
|
|
INPUT |
ApiKeyPath: Specify the API key path that is stored in the local which was given at the time of registration. This is a mandatory field. |
|
InputDocumentPath: Specify the input document path to parse the text/ json format/ table from the documents. This is a mandatory field. |
||
|
Location: Specify the location as US / EU from the drop-down. This is not a mandatory field. |
||
|
ProjectID: Specify the project ID created at the time of registration. This is a mandatory field. |
||
|
MISC |
Display Name: Displays the name of the activity. You can also customize the activity name to help troubleshoot issues faster. This name will be used for logging purposes. |
|
|
SkipOnError: It specifies whether to continue executing the workflow even if it throws an error. This supports only Boolean value “True or False”. By default, it is set to “False” True: Continues the workflow to the next step False: Stops the workflow and throws an error. |
||
|
Version: It specifies the version of the Google Document AI feature in use. |
||
|
OUTPUT |
EntitiesJson: Declare a variable to get the Json format of the specified document. This is not a mandatory field however declare a variable to get the result |
|
|
OutputText: Declare a variable to extract the text as output from the specified document. This is not a mandatory field however declare a variable to get the result |
||
|
Result: Declare and assign a variable to get the return status of the condition either as success or failure. This is not a mandatory field however declare a variable to get the result. |
||
|
TableDataset: Declare a variable to extract the output as table from the specified document. This is not a mandatory field however declare a variable to get the result. |
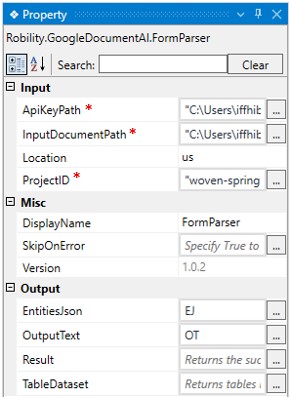
*Mandatory fields to be executed.


Use case
The following activity illustrates how to use the Form Parser activity to get the json value,
text and if any tables identified in the specified document. Here we are going to parse a
PDF document and extract the json format and text as output. In the following example,
we have already created the project ID and APIKEY path in the system. Thus, the details
are not provided here.
Steps to execute a bot
1. Open a Designer and create a solution.
2. Drag and drop the Form parse activity to the workflow.
3. Enter the API key path which has been downloaded at the time of registration
within the double quotes.
4. Enter the input document path from the system within the double quotes.
5. Enter the Project ID within the double quotes.
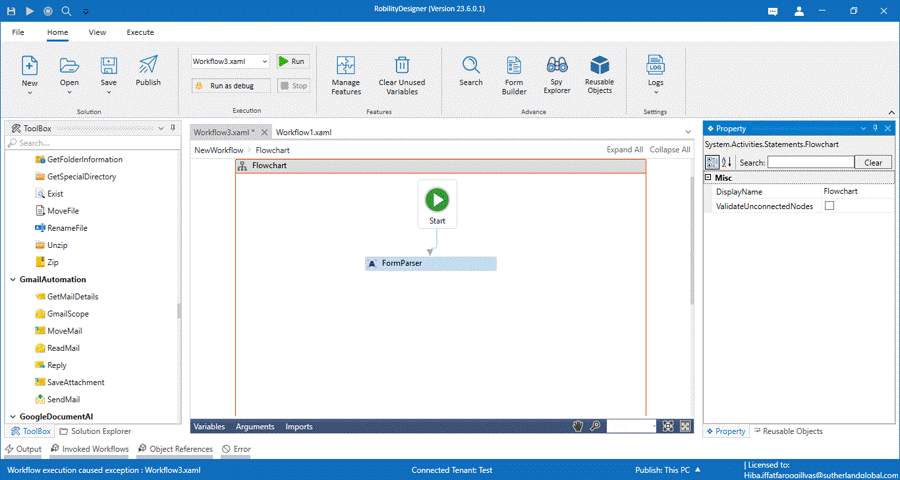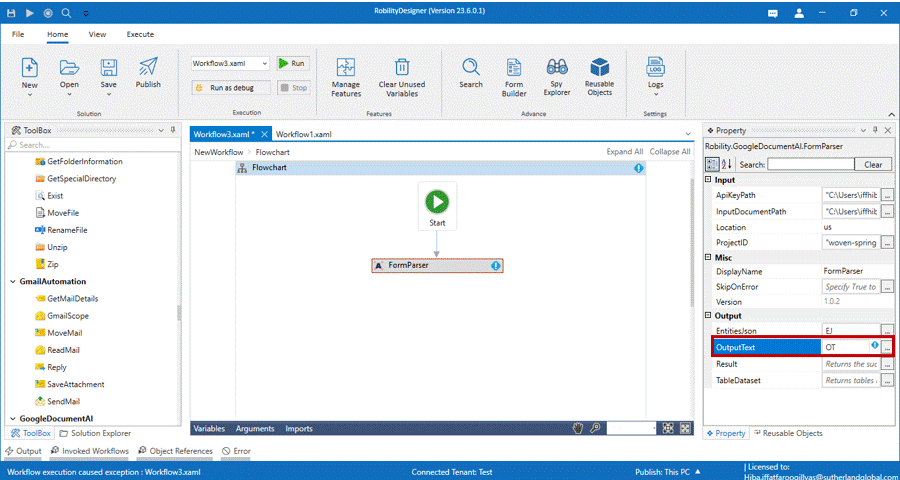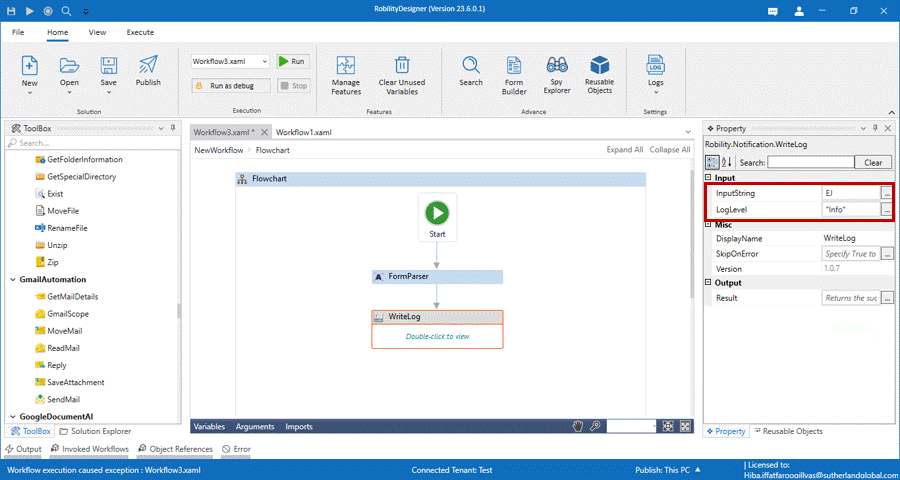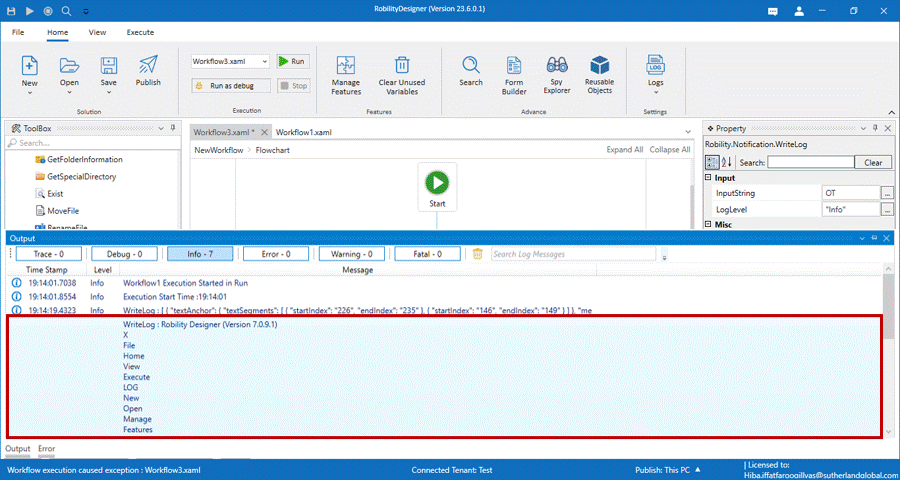
6. Declare a variable in the Entities Json as “EJ” , output text as “OT” from the
output in properties panel.
7. Connect two write log activity and enter the variables respectively in the input
string.
8. Enter the log levels as “Info”.
9. Now, execute the workflow.
The bot executes and displays the output by extracting the information as text
and Json format.