
GoogleVisionOCR
When to use the GoogleVisionOCR
This activity helps you extract the data from a non-editable images/scanned documents for further processing.
Figure 1
|
Activity Name |
Picture |
|
GoogleVisionOCR |
|
Technical Reference
|
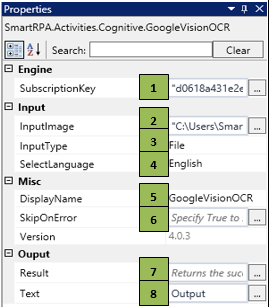
Figure 1.1
|
S.no |
Description |
|
1 |
Specify the SubscriptionKey provided by Google |
|
|
2 |
Specify the path in which the input image is stored |
|
|
3 |
InputType dropdown provides options based on the input |
|
|
4 |
SelectLanguage dropdown has multiple options to choose the preferred language |
|
|
5 |
Displays the action that the activity performs in the workflow |
|
|
6 |
Specify whether to continue executing the workflow even if the activity fails |
|
|
7 |
Specify the Boolean variable which holds the success state of the activity |
|
|
8 |
Enter the declared variable name where the extracted data has been stored |
![]() SubscriptionKey will be provided when the user registers with the Google vision services. InputType can either be a file or bytes based on the userÔÇÖs preference.
SubscriptionKey will be provided when the user registers with the Google vision services. InputType can either be a file or bytes based on the userÔÇÖs preference.
Note: The system in which the activity is executed should have internet access.
Illustration

Figure 1.2
![]()
Enter the declared variable name in the ÔÇ£TextÔÇØ field.
Figure 1.3

ÔÇï